
I’m currently working on a series of episodes for a Podcast I’ll be publishing soon. The Podcast will be in Italian and I wanted to make sure to publish the episode transcripts together with the audio episodes.
The idea of manually typing all the episodes text wasn’t really appealing to me so I started looking around.
What are the tools out there?
From a quick Google search, it seems that some companies are offering a mix of automated and human-driven transcription services.
I wasn’t really interested in that for now. I was, of course, just interested in consuming an API I could push my audio to and get back some text in a reasonable amount of time.
For this reason, I started looking for speech-to-text APIs and, of course, the usual suspects figured among the first results.
- Microsoft Cognitive Services
- IBM Watson Speech-to-Text
- SpeechMatics
- Amazon Transcribe
- Google Cloud Speech-to-Text
To be quite honest, I didn’t spend too much time investigating the solutions above. I probably spent more time reading about them to write this blog post.
I decided to go with Google Cloud because I’ve never used GCP before and wanted to give it a try. Additionally, the documentation for it seemed quite straightforward, as well as the support for Italian as language to transcribe from (the podcast is in Italian). I also had a few free credits available because I’ve never used GCP for personal use before.
Setting up
If you want to try transcribing your episodes too, follow this quick setup guide to get started.
Head over to Google Cloud and set up an account. Make sure you create a project and enable the Speech-to-Text API. If you forget to do so gcloud will be able to take care of that for you, later.

Second thing I did was installing gcloud, the CLI Google Cloud provides for interacting with the APIs. This time I was only interested in testing the API so it seemed to me that this tool was the only way to get started quickly.
Additionally, there’s not much you can do from the Google Cloud Web Console if you want to deal with Speech-to-Text APIs.
Get your file ready for transcription
Sampling rate for your audio file should be at least 16 kHz for better results. Additionally, GCP recommends a lossless codec. I only had an mp3 of my episode handy at the time so I gave it a try anyway and it worked well enough.
Make sure you know the sample rate of your file, though, because specifying a wrong one might lead to poor results.
You can usually verify the sample rate by getting info on your file from your Mac’s Finder:
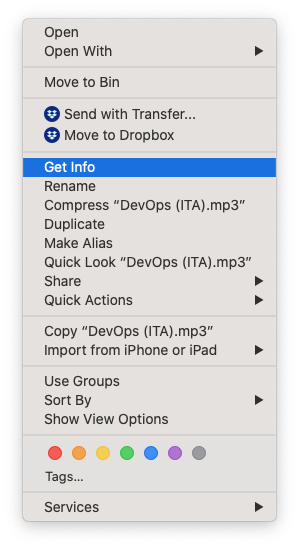

You can read more about the recommended settings on the Best Practices section.
Upload your episode to the bucket
GCP needs your file to be available from a Storage Bucket so, go ahead and create one.
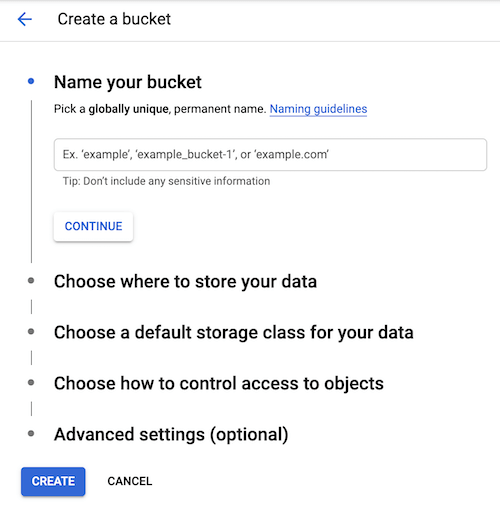
You’ll be able to upload your episode from there.
Time to transcribe
Once you have your episode file up there in the cloud go back to your local machine terminal were you have configured the gcloud tool.

If your episode lasts longer than 60 seconds (😬) you’ll want to use recognize-long-running and most likely specify --async.
As I said before, make sure you specify the right --sample-rate: in my case 44100. This will help GCP transcribe your file with better results.
The --async switch creates a long-running asynchronous operation. It took around 5 minutes for me to have the operation complete.
Oddly, I wasn’t able to find any reference to the asynchronous operation from my Google Cloud Console. So, if you want to be able to know what happened to your transcription job, make sure you take note of the operation identifier. You’ll need it to query the speech operations API for information about your transcription job.
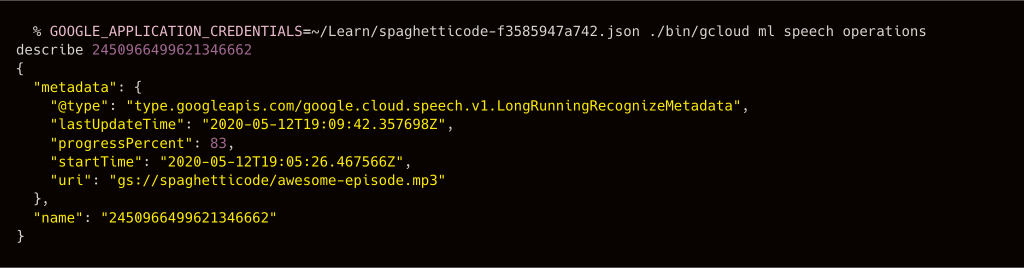
The transcribed data
Once your transcription operation is complete the describe command will return the transcript excerpts, together with the confidence rate.
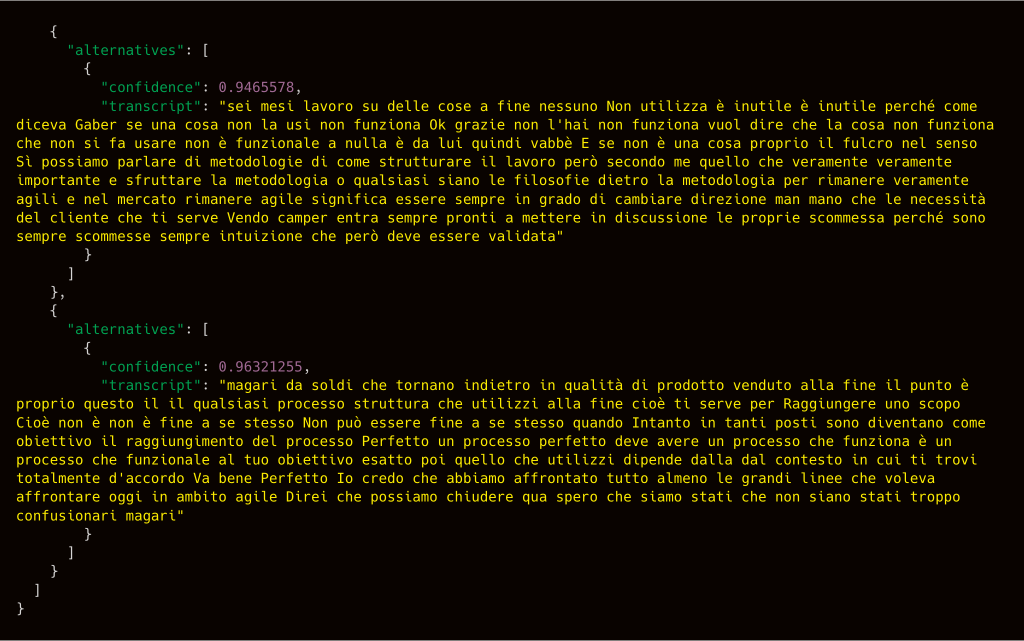
I wasn’t particularly interested in the confidence rate, I only wanted a big blob of text to be able to review and use for SEO purposes as well as to be able to include it with the episode. For this reason, jq to the resque!
I love jq, you can achieve so much with when it comes to manipulate JSON.
In my case, I only wanted to concatenate all the transcript fields and save them to a file. Here’s how I did:
$ ./bin/gcloud ml speech operations describe <your-transcription-operation-id> | jq '.response.results[].alternatives[].transcript' > my-transcript.txt
And that’s it!
Conclusion
I thought of sharing the steps above because they’ve been useful to me in producing the transcripts. I think GCP Speech-to-Text works quite well with Italian but, of course, the transcript is not suitable to be used as it is, unless your accent is perfect. Mine wasn’t 😅.
If you want to know more about my journey towards publishing my first podcast follow me on Twitter were I’ll be sharing more about it.
Photo by Malte Wingen on Unsplash
Leave a Reply