We build software to solve problems and ultimately generate value. As we do that, we create something new we need to reason about. It’s a system that evolves and becomes more complex. Managing and changing it requires understanding it: as it grows in capabilities, it will require more knowledge to be reasoned about.
Often, as the team delivers useful software for their customers, they discover additional problems to invest in solving. More problems are an opportunity to deliver more value to the customer and ultimately generate more value for the organization.
Conversely, as the organization aims to provide greater value, it must intentionally manage its product surface to ensure it remains an asset, rather than becoming a liability. This means putting in deliberate efforts to maintain the sustainability of the product organization by valuing the right signals and incentivizing the right behaviors.
Defining Product Surface

I used the term product surface, so let me clarify what I mean. I borrowed this concept from cybersecurity where it’s common to talk about attack surface to refer to the full set of entry points an attacker might use to its advantage to gain unauthorized access to a system. Just as security teams must carefully manage their attack surface, product teams must manage their product surface.
Similarly, I talk about product surface to refer to the whole set of functionality exposed to the end user that constitutes the final product. The greater the surface the higher the potential for liability: more features mean more places where bugs can occur, more business logic to account for when designing new functionality, higher chance of introducing regressions, and so on.
In cybersecurity, a larger attack surface doesn’t automatically mean worse security, but it does mean more areas to defend and monitor. Similarly, a larger product surface isn’t inherently problematic, but it requires proportionally more organizational resources to maintain effectively.
Security teams also know that every new feature potentially expands their attack surface. They work closely with development teams to evaluate security implications before adding functionality.
Product teams need similar collaboration: they should evaluate every new feature not just for its immediate value, but for how it affects their ability to maintain and evolve the entire product surface effectively and sustainably.
The Asset-Liability Spectrum
There are many posts out there that talk about code being a liability rather than an asset. They usually focus on the burden of maintaining software and the amount of value it needs to generate to compensate that burden.
To me, it’s not only about direct costs of software as an item in a balance sheet. More code requires more tests, increases the surface subject to bugs and failure, extends build times, inherently lengthens delivery times, and adds cognitive load that compounds with every new feature implemented.
New code is valuable when it generates value. At the same time, code that is not (any longer?) generating value turns into a liability. Generating value might mean different things depending on the specific context, of course, so I’ll leave that to you to define. What’s important for me to stress is that teams need to continuously assess the value that their entire product surface is producing.
Over the lifecycle of your organization the various parts of the software you build will fluidly fluctuate on a spectrum between the status of liability and asset. It’s the team’s responsibility to assess the current status and decide when it is time to cut it loose.
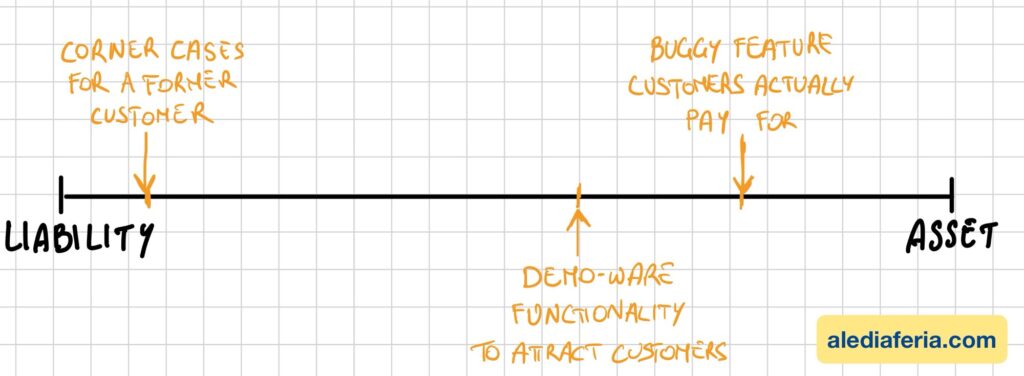
Imagine your team built a custom integration with a popular third-party service in 2020. At the time, this feature was valuable because many customers requested it. However, three years later, this integration becomes a liability when:
- The third-party service deprecates their old API that your integration relies on
- You must now maintain both the old integration for existing customers and build a new one for the updated API
- Your team spends significant time debugging edge cases that only affect a small number of users still using the old integration
- The cognitive load increases as developers need to understand both the old and new integration patterns
What you thought was going to be an asset has just turned into harder to manage product surface. More tests are going to affect your build and delivery pipeline times; you need to maintain the new functionality and ensure it keeps fitting with the whole; it also has security and cost implications.
This type of changes of status of functionality happen often and for different reasons. The net result is that the asset vs liability aspect needs to be managed pro-actively in order to have the opportunity to remove surface that hinders your team’s ability to stay efficient (the best teams I worked with strive to continuously improve, by the way).
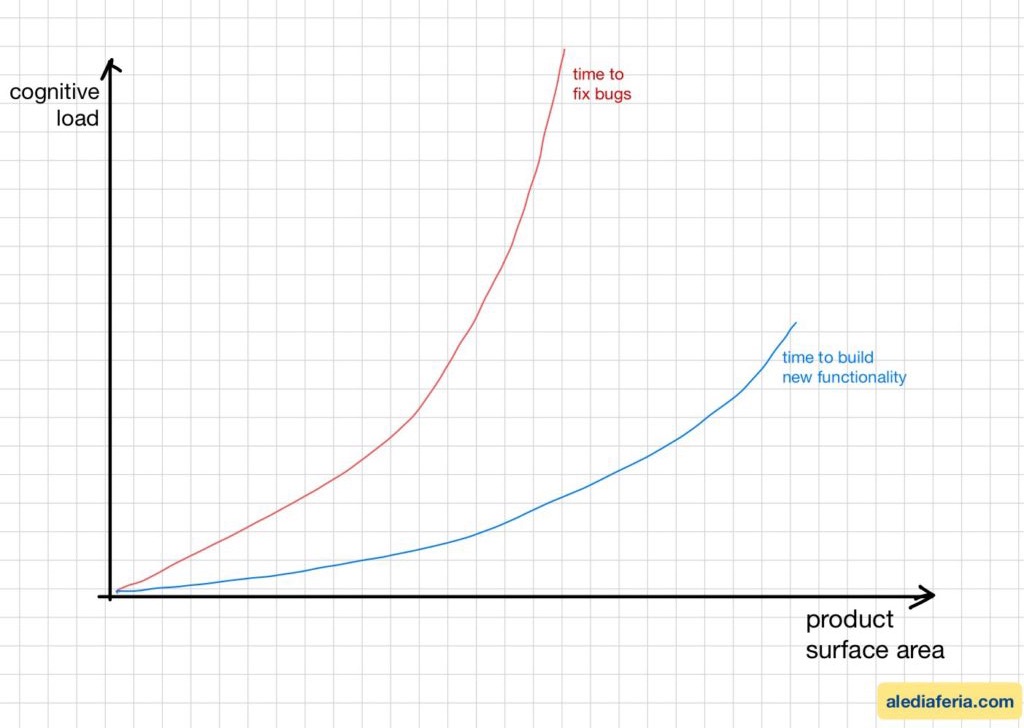
Failing to take opportunities to reduce product surface exposes your organization to a common, yet overlooked, type of liability: cognitive load.
Cognitive Load: a shared liability
Cognitive load is the amount of information one must keep in their head when making decisions. The DevEx study defines it as follows:
Cognitive load encompasses the amount of mental processing required for a developer to perform a task.
DevEx: What Actually Drives Productivity
From my perspective, cognitive load tends to increase as the product’s complexity—and consequently, the code base and infrastructure—grows. In other words, it’s about how much cognitive load each person on the team must manage to progress.
In Martin Fowler’s words:
Programmers spend most of their time modifying code. Even in a new system, almost all programming is done in the context of an existing code base. When I want to add a new feature to the software, my first task is to figure out how this feature fits into the flow of the existing application. I then need to change that flow to let my feature fit in. I often need to use data that’s already in the application, so I need to understand what the data represents, how it relates to the data around it, and what data I may need to add for my new feature.
There is only so much information one person can hold in their mental scratch pad when performing knowledge work. There are many studies that analyze the impact of cognitive load and how our brain manages temporary vs long-term memory to perform tasks. According to George A. Miller, we can keep around 7 elements of knowledge at once in our head.
Now, imagine you are developer having to make a trivial change to, how a formula computes the discount to members of an e-commerce site: at a minimum, you would need to know in which file the code for the formula is. Hopefully, you would easily find the corresponding test files, to easily validate your changes. Maybe, your new formula requires a new copy in the UI, to better convey how discounts are calculated. Now, what are you doing with customers who got a discount with the old formula, recently? Maybe you want to send them an email to inform them they will receive a voucher: where is the code to send emails? What tools are there to send emails to customers? How do you deploy this change? Is there a feature flag mechanism? Is there any marketing initiative we should sync the release of the change with?
As you can see, it’s easy to reach a sizeable amount of temporary knowledge required to reason about the change at hand. How easy it is to discover this knowledge will affect how easy it is to make the desired changes.
This is not a developer-specific issue. Product managers, test engineers, designers, and every other role involved in designing and delivering new functionality will need to maintain a shared understanding of what the product already does in order to provide useful input on how the next functionality is going to behave.
For developers, it might mean spending more time understanding existing code before making changes, leading to slower delivery times. They might miss edge cases because they couldn’t hold all the relevant scenarios in mind, resulting in subtle bugs.
For product managers, it could mean struggling to specify new features that work harmoniously with existing ones. They might overlook how a new feature conflicts with or duplicates existing functionality because the full product surface has become too complex to reason about effectively.
For designers, it often means grappling with an ever-expanding set of UI patterns and interactions that must remain consistent and intuitive. Each new feature adds another layer of complexity to the user experience that must be reconciled with existing patterns.
Organizations can measure this cognitive load through various indicators. Rising bug rates in seemingly unrelated areas might signal that teams are struggling to reason about the full system. Increasing time spent in design reviews or architecture discussions could indicate that teams need more time to understand how new changes fit into the existing product surface. Longer onboarding times for new team members might reveal that the product surface has grown too complex to quickly grasp.
The relationship between product surface and cognitive load isn’t just about complexity—it’s about the sustainability of your development process. Just as a city’s infrastructure can reach a point where adding new buildings without improving the foundation becomes unsustainable, a product can reach a point where adding new features without managing cognitive load becomes counterproductive.
This is why it’s important that the organization facilitates this positive attitude by measuring indicators that don’t just lead teams to increase the product surface, but keep a higher level lens on the overall effectiveness of the organization.
Systems of incentives
Organizations tend to optimize for what they measure. The current set of metrics is the foundation for the system of incentives that drives the decisions of the product teams.
Teams are usually measured on their ability to deliver on time (how are we tracking roadmap-wise?) and with quality (what’s the team’s bugs or regressions trend?). Why do the teams see a higher bugs rate or a slower delivery rate? The size of the product surface is hardly part of the equation when evaluating the teams’ performance but, in my experience, it is part of the answer.
Regressions in seemingly unrelated parts of the product or missed corner cases might be an indication that the team is struggling to with the cognitive load required to reason about the product area they are working on. And yet, when quality worsens, we rarely put measures in place aimed at reducing the product surface. Rather, we introduce more constraints (“every new feature release must be manually approved” or “code coverage for any new feature must be at least X%”) but keep aiming for the same if not higher throughput.
Work that is not directly correlated with customer value is frowned upon or left to an arbitrary fixed capacity for the team to work on when feature work is not enough to keep the team busy enough in the current cycle.
If your organization focuses mainly on throughput, it doesn’t give the teams the space to remove code and product surface that is not generating value. For example, it’s not uncommon for teams to struggle to justify addressing technical debt “because it doesn’t directly correlate with customer value”. This is because every effort is evaluated through the customer-value lens only.
Beyond Feature Delivery: Redefining Value
Estimating every effort solely on the basis of how much customer value it might generate provides a flawed and restricted perspective that makes your organization miss out on significant efficiency opportunities. Reducing product and code surface is not just a tidying up exercise but an actual strategic measure to maintain higher levels of performance.
To paraphrase John Cutler, if you are only measuring and facilitating output, you are going to get feature factories. But feature factories do not optimize for sustainable product surface. They optimize for ever-increasing product surface. Everything else needs to be a function of that.
Obsessing over customer value is not the problem: becoming inefficient at doing so is. We often overlook the sustainability of our existing product surface and turn into an organization that is only able to prioritize new features, because we believe that is the best way to deliver customer value.
We should not have to jump through hoops in order to be able to work on activities that have a lasting positive effect on our ability to deliver. Spending resources and capacity on removing unused features, for example, should not be a second class citizen item on our roadmap.
Should we maybe replace customer value with organizational value as our ultimate north start when making prioritization calls, then? Should the work on a new major piece of functionality, backed by observation and data, have the same value as work that reduces our cognitive load and maximizes our ability to reason about our product?
Creating a Sustainable Product Organization
An ever-increasing product surface is the result of a flawed system of incentives your organization might be operating within. As we have briefly discussed, keeping an eye on whether your product is generating the desired customer value should result in deliberate control over how sustainable your existing product offering is.
When organizations are solely incentivized to produce outputs and move on to the next item on the roadmap they miss the opportunity to course correct and maintain a healthy asset to liability ratio. Input from the product teams might become the only major driver into how the teams will allocate their capacity.
To shift from pure customer value to organizational value as a north star, organizations need new ways to measure success. These measurements should capture both the immediate impact of work and its effect on the organization’s long-term capability to deliver:
System Health Metrics:
- Change impact radius: How many parts of the system typically need modification for common changes
- Integration complexity: Number of system dependencies that need to be understood for typical features
- Code churn patterns: Areas requiring frequent modifications may indicate poorly understood or overly complex functionality
- Build and deployment times: Increasing times often signal growing system complexity
- Test coverage trends: Declining coverage in critical areas may indicate growing complexity making testing more difficult
Team Effectiveness Metrics:
- Cross-team dependencies: Number of teams typically involved in feature delivery
- Design review complexity: Time spent in design discussions versus implementation
- Feature development cycle time: Tracked by product area to identify where complexity is slowing delivery
- Regression frequency: Rate of unintended side effects from changes
Asset vs Liability Metrics:
- Feature usage versus maintenance cost
- Customer support burden per feature
- Revenue or user engagement per feature
- Technical debt accumulation rate
- Cost of delay for different types of work
These metrics help paint a more complete picture of organizational value. For example, work that reduces the change impact radius or speeds up the time to comprehension creates organizational value by improving the team’s ability to deliver future changes efficiently. Similarly, removing unused features might show no immediate customer value but could significantly reduce maintenance costs and cognitive load.
Making this shift requires a significantly higher level of organization-wide transparency. Teams need a much better understanding of what the business priorities are and they need to be empowered to make changes that might not directly translate into immediate customer value.
Organizations should establish regular cycles to review these metrics and adjust priorities accordingly. For instance, if system health metrics are trending negatively, teams might need to prioritize simplification work over new features. If team effectiveness metrics show increasing friction in certain areas, that might signal the need for architectural changes or team restructuring.
As highlighted in Cutler’s post on feature factories, same as many development teams are used to do, it’s important that the teams making product decisions have the right system of retrospectives in place so that they can measure the quality of their decisions and adjust accordingly. These retrospectives should explicitly consider both immediate outcomes and longer-term effects on organizational capability.
A Path Forward
The relationship between product surface and organizational effectiveness is complex but crucial to understand. As we’ve explored, continuously expanding product surface creates a compound effect: each new feature not only adds its own complexity but increases the cognitive load required to understand and modify the system as a whole.
This dynamic creates a challenging tension. Organizations need to deliver customer value to remain competitive, but doing so solely through feature addition leads to unsustainable growth in product surface. The solution isn’t to stop building new features – it’s to recognize product surface management as a strategic concern rather than a purely technical one.
Success requires changes at multiple levels.
First, organizations must expand their definition of value beyond immediate customer-facing features. Work that reduces cognitive load, removes unused functionality, or improves the team’s ability to understand and modify the system needs to be valued equally with new feature development.
Second, measurement systems need to evolve. Traditional metrics focusing solely on delivery speed and bug counts miss the crucial dimension of system sustainability. Teams need ways to measure and monitor their cognitive load, the effectiveness of their product surface, and their capacity to deliver change safely and confidently.
Finally, teams need to be incentivized to manage their product surface actively. This means regular evaluation of existing features, deliberate decisions about when to remove functionality, and careful consideration of how new features affect the overall system complexity.
The organizations that will thrive in the long term are those that can maintain a healthy balance between delivering new value and managing their product surface effectively. This requires a shift in mindset from seeing software solely as an asset to understanding it as a dynamic system that requires continuous curation to remain effective.
The question isn’t whether to manage product surface – it’s how to do so deliberately and effectively.
Leave a Reply